KDD是数据挖掘与知识发现(DataMiningandKnowledgeDiscovery)的简称,KDDCUP是由ACM(AssociationforComputingMachiner)的SIGKDD(SpecialInterestGrouponKnowledgeDiscoveryandDataMining)组织的年度竞赛。
”KDDCUP99dataset”是KDD竞赛在1999年举行时采用的数据集。从官网下载KDD99数据集,如下图所示:
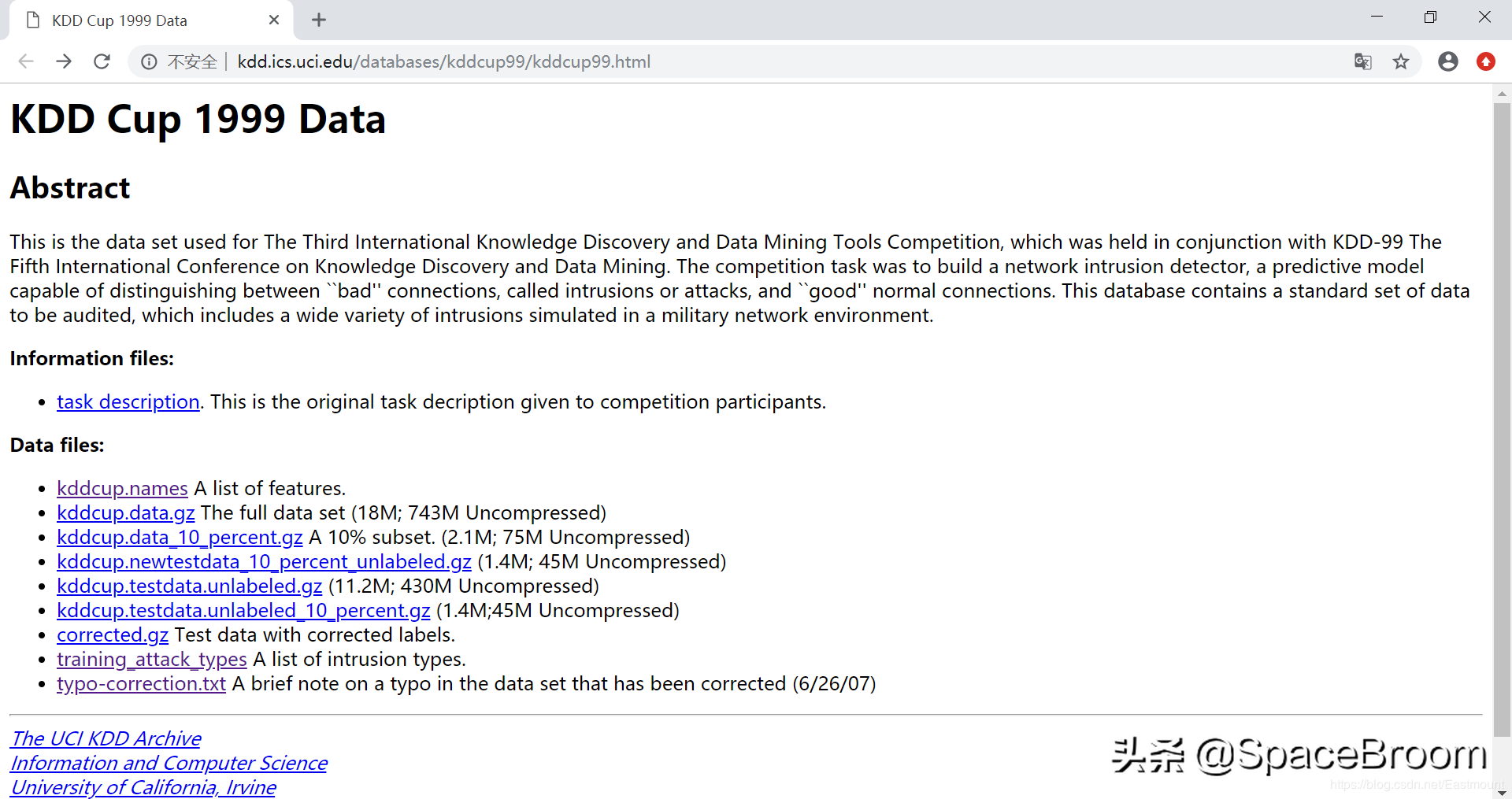
KDDCup1999数据集:是与KDD-99第五届知识发现和数据挖掘国际会议同时举行的第三届国际知识发现和数据挖掘工具竞赛使用的数据集。竞争任务是建立一个网络入侵检测器,这是一种能够区分称为入侵或攻击的“不良”连接和“良好”的正常连接的预测模型。该数据集包含一组要审核的标准数据,其中包括在军事网络环境中模拟的多种入侵。
数据文件包括:
功能列表。完整数据集(18M;743M未压缩)_10_%的数据集(2.1M;75M未压缩)_10_percent_(1.4M;45M未压缩)(11.2M;430M未压缩)_10_(1.4M;45M未压缩)正确标签的测试数据training_attack_types入侵类型列表关于数据集中的简要说明
1998年美国国防部高级规划署(DARPA)在MIT林肯实验室进行了一项入侵检测评估项目。林肯实验室建立了模拟美国空军局域网的一个网络环境,收集了9周时间的TCPdump()网络连接和系统审计数据,仿真各种用户类型、各种不同的网络流量和攻击手段,使它就像一个真实的网络环境。这些TCPdump采集的原始数据被分为两个部分:7周时间的训练数据,大概包含5,000,000多个网络连接记录,剩下的2周时间的测试数据大概包含2,000,000个网络连接记录。
一个网络连接定义为在某个时间内从开始到结束的TCP数据包序列,并且在这段时间内,数据在预定义的协议下(如TCP、UDP)从源IP地址到目的IP地址的传递。每个网络连接被标记为正常(normal)或异常(attack),异常类型被细分为4大类共39种攻击类型,其中22种攻击类型出现在训练集中,另有17种未知攻击类型出现在测试集中。
4种异常类型分别是:
DOS(denial-of-service)拒绝服务攻击,例如ping-of-death,synflood,smurf等。
R2L(unauthorizedaccessfromaremotemachinetoalocalmachine)来自远程主机的未授权访问,例如guessingpassword。
U2R(unauthorizedaccesstolocalsuperuserprivilegesbyalocalunpivilegeduser)未授权的本地超级用户特权访问,例如bufferoverflowattacks。
PROBING(surveillanceandprobing)端口监视或扫描,例如port-scan,ping-sweep等。
随后来自哥伦比亚大学的SalStolfo教授和来自北卡罗莱纳州立大学的WenkeLee教授采用数据挖掘等技术对以上的数据集进行特征分析和数据预处理,形成了一个新的数据集。该数据集用于1999年举行的KDDCUP竞赛中,成为著名的KDD99数据集。虽然年代有些久远,但KDD99数据集仍然是网络入侵检测领域的事实Benckmark,为基于计算智能的网络入侵检测研究奠定基础。
二.数据特征描述下载的数据集如下图所示,这里以10%的数据集来进行实验。
_10_percent_corrected
_10_percent
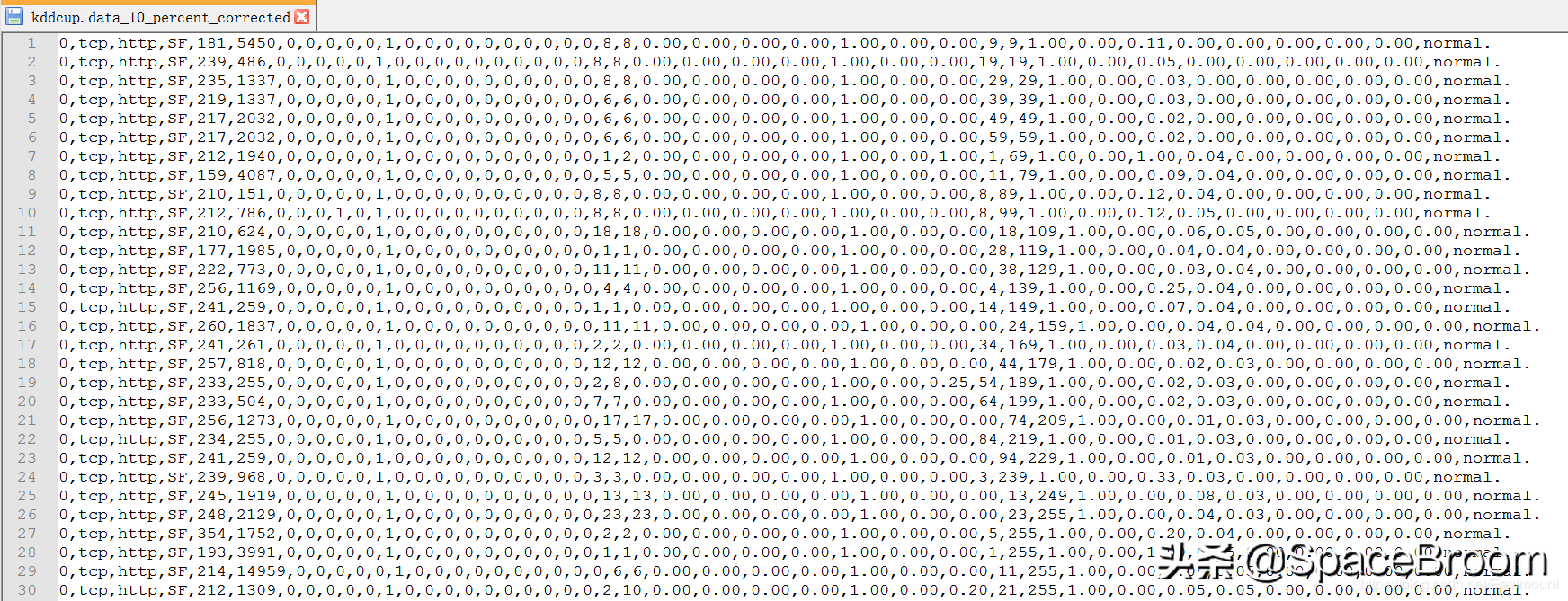
下面展现了其中3条记录,总共有42项特征,最后一列是标记特征(Label),其他前41项特征共分为四大类。
TCP连接基本特征(共9种,序号1~9)
TCP连接的内容特征(共13种,序号10~22)
基于时间的网络流量统计特征(共9种,序号23~31)
基于主机的网络流量统计特征(共10种,序号32~41)
接下来按顺序解释各个特征的具体含义,这是进行数据分析之前非常必要的一个环节。
1.TCP连接基本特征(共9种,序号1~9)
基本连接特征包含了一些连接的基本属性,如连续时间,协议类型,传送的字节数等。
(1)duration-连接持续时间,以秒为单位,连续类型。范围是[0,58329]。它的定义是从TCP连接以3次握手建立算起,到FIN/ACK连接结束为止的时间;若为UDP协议类型,则将每个UDP数据包作为一条连接。数据集中出现大量的duration=0的情况,是因为该条连接的持续时间不足1秒。
(2)protocol_type-协议类型,离散类型,共有3种:TCP,UDP,ICMP。
(3)service-目标主机的网络服务类型,离散类型,共有70种。’aol’,‘auth’,‘bgp’,‘courier’,‘csnet_ns’,‘ctf’,‘daytime’,‘discard’,‘domain’,‘domain_u’,‘echo’,‘eco_i’,‘ecr_i’,‘efs’,‘exec’,‘finger’,‘ftp’,‘ftp_data’,‘gopher’,‘harvest’,‘hostnames’,‘http’,‘http_2784′,‘http_443′,‘http_8001′,‘imap4′,‘IRC’,‘iso_tsap’,‘klogin’,‘kshell’,‘ldap’,‘link’,‘login’,‘mtp’,‘name’,‘netbios_dgm’,‘netbios_ns’,‘netbios_ssn’,‘netstat’,‘nnsp’,‘nntp’,‘ntp_u’,‘other’,‘pm_dump’,‘pop_2′,‘pop_3′,‘printer’,‘private’,‘red_i’,‘remote_job’,‘rje’,‘shell’,‘smtp’,‘sql_net’,‘ssh’,‘sunrpc’,‘supdup’,‘systat’,‘telnet’,‘tftp_u’,‘tim_i’,‘time’,‘urh_i’,‘urp_i’,‘uucp’,‘uucp_path’,‘vmnet’,‘whois’,‘X11′,‘Z39_50′。
(4)flag-连接正常或错误的状态,离散类型,共11种。’OTH’,‘REJ’,‘RSTO’,‘RSTOS0′,‘RSTR’,‘S0′,‘S1′,‘S2′,‘S3′,‘SF’,‘SH’。它表示该连接是否按照协议要求开始或完成。例如SF表示连接正常建立并终止;S0表示只接到了SYN请求数据包,而没有后面的SYN/ACK。其中SF表示正常,其他10种都是error。
(5)src_bytes-从源主机到目标主机的数据的字节数,连续类型,范围是[0,1379963888]。
(6)dst_bytes-从目标主机到源主机的数据的字节数,连续类型,范围是[0.1309937401]。
(7)land-若连接来自/送达同一个主机/端口则为1,否则为0,离散类型,0或1。
(8)wrong_fragment-错误分段的数量,连续类型,范围是[0,3]。
(9)urgent-加急包的个数,连续类型,范围是[0,14]。
2.TCP连接的内容特征(共13种,序号10~22)
对于U2R和R2L之类的攻击,由于它们不像DoS攻击那样在数据记录中具有频繁序列模式,而一般都是嵌入在数据包的数据负载里面,单一的数据包和正常连接没有什么区别。为了检测这类攻击,WenkeLee等从数据内容里面抽取了部分可能反映入侵行为的内容特征,如登录失败的次数等。
(10)hot-访问系统敏感文件和目录的次数,连续,范围是[0,101]。例如访问系统目录,建立或执行程序等。
(11)num_failed_logins-登录尝试失败的次数。连续,[0,5]。
(12)logged_in-成功登录则为1,否则为0,离散,0或1。
(13)num_compromised-compromised条件出现的次数,连续,[0,7479]。
(14)root_shell-若获得rootshell则为1,否则为0,离散,0或1。root_shell是指获得超级用户权限。
(15)su_attempted-若出现”suroot”命令则为1,否则为0,离散,0或1。
(16)num_root-root用户访问次数,连续,[0,7468]。
(17)num_file_creations-文件创建操作的次数,连续,[0,100]。
(18)num_shells-使用shell命令的次数,连续,[0,5]。
(19)num_access_files-访问控制文件的次数,连续,[0,9]。例如对/etc/passwd或.rhosts文件的访问。
(20)num_outbound_cmds-一个FTP会话中出站连接的次数,连续,0。数据集中这一特征出现次数为0。
(21)is_hot_login-登录是否属于“hot”列表,是为1,否则为0,离散,0或1。例如超级用户或管理员登录。
(22)is_guest_login-若是guest登录则为1,否则为0,离散,0或1。
3.基于时间的网络流量统计特征(共9种,序号23~31)
由于网络攻击事件在时间上有很强的关联性,因此统计出当前连接记录与之前一段时间内的连接记录之间存在的某些联系,可以更好的反映连接之间的关系。这类特征又分为两种集合:一个是“samehost”特征,只观察在过去两秒内与当前连接有相同目标主机的连接,例如相同的连接数,在这些相同连接与当前连接有相同的服务的连接等等;另一个是“sameservice”特征,只观察过去两秒内与当前连接有相同服务的连接,例如这样的连接有多少个,其中有多少出现SYN错误或者REJ错误。
(23)count-过去两秒内,与当前连接具有相同的目标主机的连接数,连续,[0,511]。
(24)srv_count-过去两秒内,与当前连接具有相同服务的连接数,连续,[0,511]。
(25)serror_rate-过去两秒内,在与当前连接具有相同目标主机的连接中,出现“SYN”错误的连接的百分比,连续,[0.00,1.00]。
(26)srv_serror_rate-过去两秒内,在与当前连接具有相同服务的连接中,出现“SYN”错误的连接的百分比,连续,[0.00,1.00]。
(27)rerror_rate-过去两秒内,在与当前连接具有相同目标主机的连接中,出现“REJ”错误的连接的百分比,连续,[0.00,1.00]。
(28)srv_rerror_rate-过去两秒内,在与当前连接具有相同服务的连接中,出现“REJ”错误的连接的百分比,连续,[0.00,1.00]。
(29)same_srv_rate-过去两秒内,在与当前连接具有相同目标主机的连接中,与当前连接具有相同服务的连接的百分比,连续,[0.00,1.00]。
(30)diff_srv_rate-过去两秒内,在与当前连接具有相同目标主机的连接中,与当前连接具有不同服务的连接的百分比,连续,[0.00,1.00]。
(31)srv_diff_host_rate-过去两秒内,在与当前连接具有相同服务的连接中,与当前连接具有不同目标主机的连接的百分比,连续,[0.00,1.00]。
注意:这一大类特征中,23、25、27、29、30这5个特征是“samehost”特征,前提都是与当前连接具有相同目标主机的连接;24、26、28、31这4个特征是“sameservice”特征,前提都是与当前连接具有相同服务的连接。
4.基于主机的网络流量统计特征(共10种,序号32~41)
基于时间的流量统计只是在过去两秒的范围内统计与当前连接之间的关系,而在实际入侵中,有些Probing攻击使用慢速攻击模式来扫描主机或端口,当它们扫描的频率大于2秒的时候,基于时间的统计方法就无法从数据中找到关联。所以WenkeLee等按照目标主机进行分类,使用一个具有100个连接的时间窗,统计当前连接之前100个连接记录中与当前连接具有相同目标主机的统计信息。
(32)dst_host_count-前100个连接中,与当前连接具有相同目标主机的连接数,连续,[0,255]。
(33)dst_host_srv_count-前100个连接中,与当前连接具有相同目标主机相同服务的连接数,连续,[0,255]。
(34)dst_host_same_srv_rate-前100个连接中,与当前连接具有相同目标主机相同服务的连接所占的百分比,连续,[0.00,1.00]。
(35)dst_host_diff_srv_rate-前100个连接中,与当前连接具有相同目标主机不同服务的连接所占的百分比,连续,[0.00,1.00]。
(36)dst_host_same_src_port_rate-前100个连接中,与当前连接具有相同目标主机相同源端口的连接所占的百分比,连续,[0.00,1.00]。
(37)dst_host_srv_diff_host_rate-前100个连接中,与当前连接具有相同目标主机相同服务的连接中,与当前连接具有不同源主机的连接所占的百分比,连续,[0.00,1.00]。
(38)dst_host_serror_rate-前100个连接中,与当前连接具有相同目标主机的连接中,出现SYN错误的连接所占的百分比,连续,[0.00,1.00]。
(39)dst_host_srv_serror_rate-前100个连接中,与当前连接具有相同目标主机相同服务的连接中,出现SYN错误的连接所占的百分比,连续,[0.00,1.00]。
(40)dst_host_rerror_rate-前100个连接中,与当前连接具有相同目标主机的连接中,出现REJ错误的连接所占的百分比,连续,[0.00,1.00]。
(41)dst_host_srv_rerror_rate-前100个连接中,与当前连接具有相同目标主机相同服务的连接中,出现REJ错误的连接所占的百分比,连续,[0.00,1.00]。
5.样本分析
WeLee等人在处理原始连接数据时将部分重复数据去除,例如进行DoS攻击时产生大量相同的连接记录,就只取攻击过程中5分钟内的连接记录作为该攻击类型的数据集。同时,也会随机抽取正常(normal)数据连接作为正常数据集。KDD99数据集总共由500万条记录构成,它还提供一个10%的训练子集和测试子集,它的样本类别分布如下:
NORMAL:正常访问,训练集(10%)有97278个样本,测试集(Corrected)有60593个样本。
PROBE:端口监视或扫描,训练集(10%)有4107个样本,测试集(Corrected)有4166个样本。攻击包括:ipsweep、mscan、nmap、portsweep、saint、satan。
DOS:拒绝服务攻击,训练集(10%)有391458个样本,测试集(Corrected)有229853个样本。攻击包括:apache2、back、land、mailbomb、neptune、pod、processtable、smurf、teardrop、udpstorm。
U2R:未授权的本地超级用户特权访问,训练集(10%)有52个样本,测试集(Corrected)有228个样本。攻击包括:buffer_overflow、httptunnel、loadmodule、perl、ps、rootkit、sqlattack、xterm。
R2L:来自远程主机的未授权访问,训练集(10%)有1126个样本,测试集(Corrected)有16189个样本。攻击包括:ftp_write、guess_passwd、imap、multihop、named、phf、smail、snmpgetattack、snmpguess、spy、warezclient、warezmaster、worm、xlock、xsnoop。
注意:
(1)KDD99将攻击类型分为4类,然后又细分为39小类,每一类代表一种攻击类型,类型名被标记在训练数据集每一行记录的最后一项。
(2)某些攻击类型只在测试集(或训练集)中出现,而未在训练集(或测试集)中出现。比如10%的数据集中,训练集中共出现了22个攻击类型,而剩下的17种只在测试集中出现,这样设计的目的是检验分类器模型的泛化能力,对未知攻击类型的检测能力是评价入侵检测系统好坏的重要指标。
三.Python数据处理1.KDD99数据集评价
入侵检测
入侵检测的方法从根本上讲就是设计一个分类器,能将数据流中的正常与异常数据区分出来,从而实现对攻击行为的报警。本文KDD99数据集的目的就是为入侵检测系统提供统一的性能评价基准,常用来在学术圈检验入侵检测算法的好坏。本文将数据集中的10%训练集来训练分类器,然后用corrected测试集测试分类器性能,这个分类器可以是基于贝叶斯的、决策树的、神经网络的或者是支持向量机的。
特征选择
特征选择是KDD99数据集的另一个主要应用。KDD99数据集中,每个连接有41个特征,对于一个分类器来说,要从这么多特征中提取规则是费时且不精确的,这体现在一些无关或冗余的特征往往会降低分类器模型的检测精度和速度。而且对于从原始的tcpdump数据中提取特征这一过程,也将是困难和费时的,这对于在线入侵检测系统是致命的。因此去除冗余特征或不重要特征,对于提高分类器训练速度和检测精度来说,是必要的。要说明的是对于不同的分类器来说,最优的特征子集可以是不同的。
数据集评价
KDD99数据集是入侵检测领域的Benchmark(基准),为基于计算智能的网络入侵检测研究奠定了基础,从那以后很多学者开始研究入侵检测算法,当然不能不提到众所周知的“功夫网”,实际上它就是一个大规模的入侵检测系统。KDD99从1999年创建已经过去多年,当年的实验条件和攻击手段放到今天早已过时,而且从原来的网络层攻击进化为针对应用层的攻击,例如跨站脚本、数据库注入等等(当然,针对应用层攻击自有新的解决方案)。你可以说,要解决这个问题,重新做一遍98年那个实验,用新的设备新的攻击手段,产生新的数据集不就行了吗?事实是据我所知还没有学术组织公开新的且质量较高的数据集,安全软件公司里肯定有足够的数据库,当然,人家是不会共享出来的,就靠这个赚钱。另一个解决办法是你自己搭建网络环境,自己做实验,就是累点,当然可行。
所以,希望这篇基础性文章对您有所帮助。
2.字符型转换为数值型在数据挖掘的过程中,数据的预处理一直都是非常重要的一个环节,只有把数据转化为分类器认可的形式才可以对其进行训练。
(1)有效地将数据集中字符型转换为数值型,这是数据集预处理常见的方法。
(2)训练集和测试集的类标不同,通过全局变量动态增加新类标,对未知类型的检测是评价算法的重要指标。
label_list为全局变量globallabel_list文件写入操作data_file=open(handled_file,'w')定义将源文件行中3种协议类型转换成数字标识的函数defhandleProtocol(inputs):protocol_list=['tcp','udp','icmp']ifinputs[1]inprotocol_list:returnfind_index(inputs[1],protocol_list)[0]定义将源文件行中11种网络连接状态转换成数字标识的函数defhandleFlag(inputs):flag_list=['OTH','REJ','RSTO','RSTOS0','RSTR','S0','S1','S2','S3','SF','SH']ifinputs[3]inflag_list:returnfind_index(inputs[3],flag_list)[0]在函数内部使用全局变量并修改它globallabel_listifinputs[41]inlabel_list:returnfind_index(inputs[41],label_list)[0]else:label_(inputs[41])returnfind_index(inputs[41],label_list)[0]循环读取文件数据withopen(source_file,'r')asdata_source:csv_reader=(data_source)csv_writer=(data_file)count=0将源文件行中3种协议类型转换成数字标识temp_line[2]=handleService(row)将源文件行中11种网络连接状态转换成数字标识temp_line[41]=handleLabel(row)输出每行数据中所修改后的状态-*-coding:utf-8-*-importosimportcsvimportnu_selectionimporttrain_test_创建line_nums行para_num列的矩阵x_mat=((line_nums,41))y_label=[]前41个特征y_(item_mat[-1])-----------------------------------------第二步划分数据集-----------------------------------------y=[]forniny_label:(int(n))y=(y,dtype=int)划分数据集测试集40%train_data,test_data,train_target,test_target=train_test_split(x_mat,y,test_size=0.4,random_state=42)printtrain_,train__,test_第四步评价算法-----------------------------------------printsum(result==test_target)准确率召回率F值Z-scorenormaliaztiondefZscoreNormalization(x):x=((x))/(x)returnx
针对该数据集,通过标注化处理连续型特征,具体公式如下:
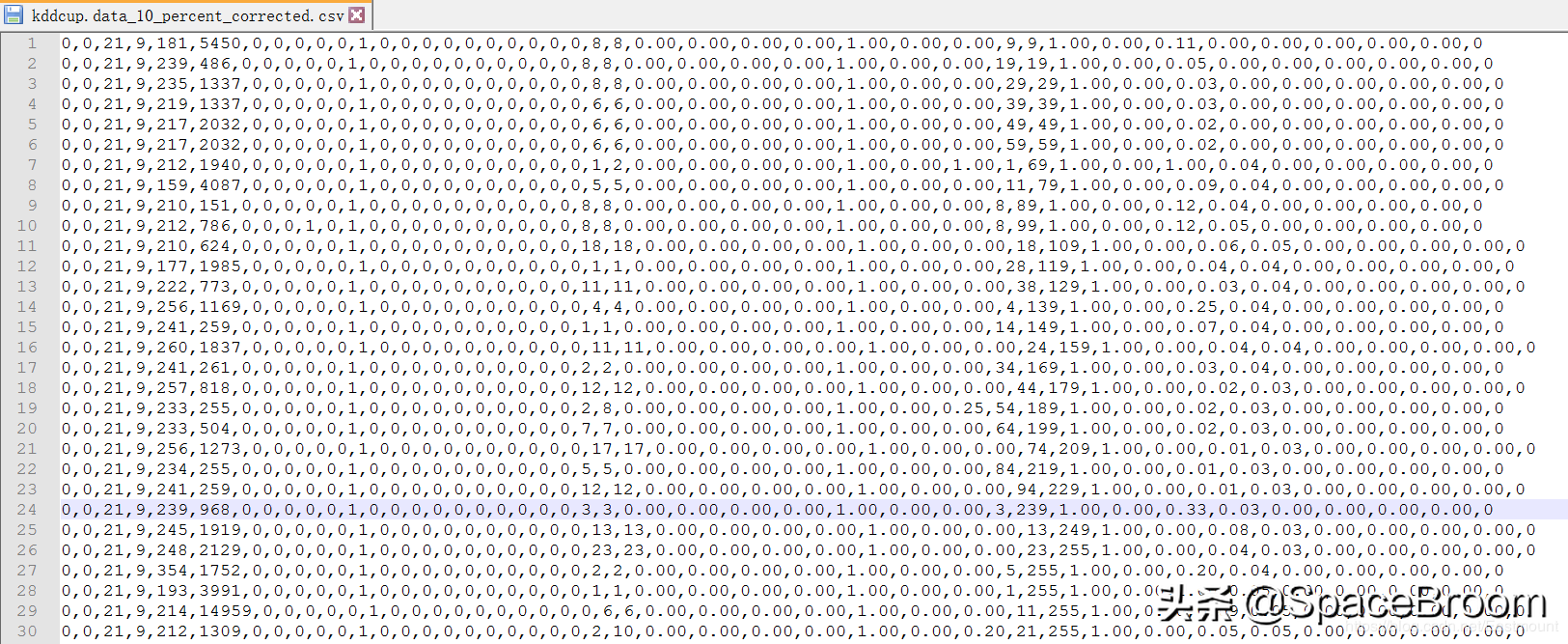
其中,AVG为平均值,STAD为平均绝对偏差,如果AVG等于0,则X’=0;如果STD等于0,则X’=0。
核心代码如下所示,这里建议读者直接使用我的数据集或测试数据集测试,否则花费巨大时间。
全局变量globalx_mat-------------------------------------读取文件划分数据集-----------------------------------------fr=open("")data_file=open("",'wb+')lines=()line_nums=len(lines)print(line_nums)划分数据集foriinrange(line_nums):line=lines[i].strip()item_mat=(',')x_mat[i,:]=item_mat[0:42]--------------------------------获取某列特征并依次标准化并赋值-----------------------------print(len(x_mat[:,0]))获取某行数据42durationZscoreNormalization(x_mat[:,0],4)dst_bytesZscoreNormalization(x_mat[:,0],7)urgentZscoreNormalization(x_mat[:,0],9)num_failed_loginsZscoreNormalization(x_mat[:,0],12)su_attempteZscoreNormalization(x_mat[:,0],15)num_file_creationsZscoreNormalization(x_mat[:,0],17)num_access_filesZscoreNormalization(x_mat[:,0],19)countZscoreNormalization(x_mat[:,0],23)serror_rateZscoreNormalization(x_mat[:,0],25)rerror_rateZscoreNormalization(x_mat[:,0],27)same_srv_rateZscoreNormalization(x_mat[:,0],29)srv_diff_host_rateZscoreNormalization(x_mat[:,0],31)dst_host_srv_countZscoreNormalization(x_mat[:,0],33)dst_host_diff_srv_rateZscoreNormalization(x_mat[:,0],35)dst_host_srv_diff_host_rateZscoreNormalization(x_mat[:,0],37)dst_host_srv_serror_rateZscoreNormalization(x_mat[:,0],39)dst_host_srv_rerror_:utf-8importnumpyasnpimportpandasaspdimportcsv数据归一化defMinmaxNormalization(x,n):print(len(x))i=0whileilen(x):x_mat[i][n]=(x[i]-(x))/((x)-(x))print(x_mat[i][n])i=i+1print("The",n,"featureisnormal.")创建line_nums行para_num列的矩阵x_mat=((line_nums,42))获取42个特征()print(x_)获取某列数据494021print(len(x_mat[0,:]))归一化处理MinmaxNormalization(x_mat[:,0],0)src_bytesMinmaxNormalization(x_mat[:,0],5)wrong_fragmentMinmaxNormalization(x_mat[:,0],8)hotMinmaxNormalization(x_mat[:,0],10)num_compromisedMinmaxNormalization(x_mat[:,0],14)num_rootMinmaxNormalization(x_mat[:,0],16)num_shellsMinmaxNormalization(x_mat[:,0],18)num_outbound_cmdsMinmaxNormalization(x_mat[:,0],22)srv_countMinmaxNormalization(x_mat[:,0],24)srv_serror_rateMinmaxNormalization(x_mat[:,0],26)srv_rerror_rateMinmaxNormalization(x_mat[:,0],28)diff_srv_rateMinmaxNormalization(x_mat[:,0],30)dst_host_countMinmaxNormalization(x_mat[:,0],32)dst_host_same_srv_rateMinmaxNormalization(x_mat[:,0],34)dst_host_same_src_port_rateMinmaxNormalization(x_mat[:,0],36)dst_host_serror_rateMinmaxNormalization(x_mat[:,0],38)dst_host_rerror_rateMinmaxNormalization(x_mat[:,0],40)文件写入操作csv_writer=(data_file)i=0whileilen(x_mat[:,0]):csv_(x_mat[i,:])i=i+1data_()输出结果如下图所示:
3.KNN检测及评估
最后代码如下所示,主要包括以下功能:
针对上面标准化和归一化处理后的数据集,进行KNN算法分类
采用欧式距离计算,并绘制散点分布图(序列号、最小欧式距离、类标)
ROC曲线评估
但实验效果非常不理想,不知道什么具体原因,哎,心累~博友们使用的时候帮忙检测下前面的标准化和归一化代码是否正确。
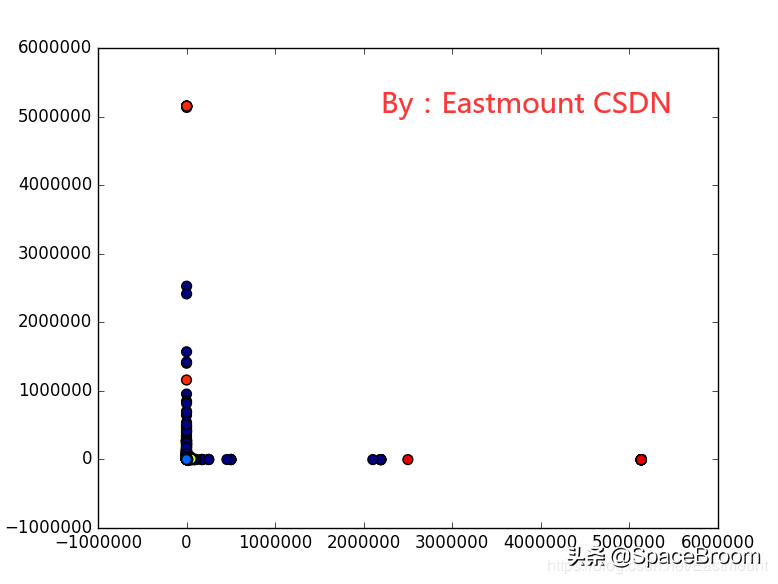
-----------------------------------------第一步加载数据集-----------------------------------------fr=open("_10_")lines=()line_nums=len(lines)print(line_nums)划分数据集foriinrange(line_nums):line=lines[i].strip()item_mat=(',')x_mat[i,:]=item_mat[0:31]类标()print(x_)print(len(y_label))list转换数组-----------------------------------------第三步KNN训练-----------------------------------------defclassify(input_vct,data_set):data_set_size=data_[0]矩阵中每个元素都平方distance=sq_diff_(axis=1)**0.5返回最小距离test_size=len(test_target)result=((test_size,3))foriinrange(test_size):矩阵转置result=(result)输出ROC曲线二维矩阵欧式距离最大值forjinrange(1000):threshold=max_dis/1000*jnormal1=0abnormal1=0forkinrange(data_set_size):ifdata_set[1][k]thresholdanddata_set[2][k]==1:normal1+=1ifdata_set[1][k]thresholdanddata_set[2][k]!=1:abnormal1+=1roc_rate[0][j]=normal1/normal阈值以上异常点/全体异常点returnroc_rate横轴为序号纵轴为最小欧氏距离图2ROC曲线纵轴检测率:即阈值以上异常点/全体异常点roc_rate=roc(result)(2)(roc_rate[0],roc_rate[1],edgecolors='None',s=1,alpha=1)()4.Github代码分享运行结果如下图所示,本篇文章所有资源参考我的Github。
横坐标序号,纵坐标最小欧式距离,散点颜色类标(正常、攻击)。
ROC曲线:
扩充input_vct到与data_set同型并相减sq_diff_mat=diff_mat**2每行相加求和并开平方根(axis=0)创建line_nums行para_num列的矩阵class_label=[]foriinrange(line_nums):line=lines[i].strip()item_mat=(',')result_mat[i,:]=item_mat[0:para_num]class_(item_mat[-1])阈值以上正常点/全体正常的点roc_rate[1][j]=abnormal1/abnormal序号最小欧氏距离测试集数据类别result=(result)图1散点图:横轴为序号,纵轴为最小欧氏距离,点中心颜色根据测试集数据类别而定,点外围无颜色,点大小为最小1,灰度为最大1roc_rate=roc(result)(2)(roc_rate[0],roc_rate[1],edgecolors='None',s=1,alpha=1)#图2ROC曲线:横轴误报率,即阈值以上正常点/全体正常的点;纵轴检测率,即阈值以上异常点/全体异常点()if__name__=="__main__":test('','')六.总结写到这里,这篇基于机器学习的入侵检测和攻击识别分享完毕。严格意义上来说,这篇文章是数据分析,它有几个亮点:
(1)详细介绍了数据分析预处理中字符特征转换为数值特征、数据标准化、数据归一化,这都是非常基础的工作。
(2)结合入侵检测应用KNN实现分类。
(3)绘制散点图采用序号、最小欧式距离、类标,ROC曲线绘制都是之前没分享的。
(4)恶意代码或入侵检测,后续作者还会深入,包括源代码、二进制分析。
这篇文章中也有几个不足之处:
(1)最后的实验效果非常不理想,但本文的整体思路是值得学习的,推荐各位从我的Github下载学习。
(2)后续作者尝试结合深度学习、图像识别来进行恶意代码分析。
(3)作者刚刚学习安全领域,还非常菜,还有太多要学习的知识,但会一直努力的。
总之,希望基础性文章对您有所帮助,如果文章中有错误或不足之处,还请提出和海涵,希望与您共同进步。
天行健,君子以自强不息。
地势坤,君子以厚德载物。



